一、简介
Redis是一种高性能的NoSQL(not only sql)非关系型数据库,key-value存储。key可以是任意类型,redis底层会转换为string。而value可以是五种的基本类型。
二、启动、状态、结束
1 | systemctl start redis-server |
默认端口时6379
有16个数据库,每一个从下标0开始
统一管理密码,16个库同样密码
1 | redis-server //启动redis服务 |
三、基本类型
3.1 String类型
key | value(int/string/float)
set key value
get key
incr key 自增
1 | set string1 liao |
底层数据结构简单动态字符串(SDS)
C语言’\0’作为字符串结尾,而redis的key是任意类型的,如果s=”hello\0world”,’\0’后面的字符串会被截断,不安全,因此Redis重新定义SDS这种数据结构。
应用场景:
1、缓存:查询MySQL前先查询Redis
2、计数:文章的阅读数、视频播放次数,通过incr命令对应次数会加一。
3、共享session:在分布式系统中,用Redis集中管理session,Session数据从Redis中获取即可。(session共享会话)
3.2 Hash类型(散列类型)
key->val 一个键只能对应一个值
hset 插入
hget通过key取出值
hmget取出多个
hlen容器中多少个元素
1 | hset hash1 key1 12 |
Hash类型的键是由以下两种数据结构作为底层实现:
1、压缩列表(ziplist);压缩列表比字典更节省内存,因此在创建新hash键时,默认时用压缩列表作为底层实现
2、字典(哈希表)
(当ziplist元素超过512,会变成哈希表,或者单个元素大小超过64byte,会变为哈希表)
3.3 List类型
lpush 从左边插入元素
rpop从右边取出元素 (取出来之后会从内存中删除)
llen 容器中元素的个数
1 | rpush key value //从右边插入 |
底层数据结构是:
1、双端链表(quickest)
2、压缩列表(ziplist)
使用场景:
1、消息队列(lpush + rpop / rpush + lpop )
2、栈(lpush+lpop / rpush+rpop)
3.4 Set类型
sadd增加元素
scard查看容器元素个数
srem删除容器元素
sismember查看是否有某个元素
1 | sadd set1 12 1 2 3 100 99 98 1 2 3 |
底层数据结构:
1、数组O(n):当数据可以用整数表示时,Set合集会被编码为inset的数据结构。
2、哈希表O(1):value为空的字典(dict),当元素个数大于512(可以配置)、或者元素无法用整形表示时,则用哈希表编码
使用场景
1、给用户打标签
2、抽奖
1 | standmember key [count] //随机获取count个元素 |
3.5 Zset (Sort Set)类型
score和value是一个整体
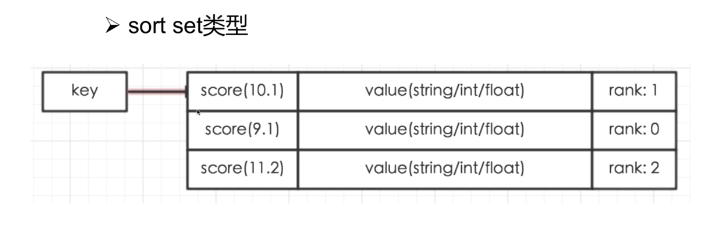
1 | zadd zset1 10.1 val1 |
底层数据结构
1、压缩列表
2、跳表
应用场景:
1、排行榜
四、使用Redis的优势
1.查询速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
支持丰富数据类型,支持string,list,set,sorted set,hash
丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
单线程,Redis利用队列技术将并发访问变为串行访问,消除了传统数据库串行控制的开销
支持事务