一、简介
哈希表在待查关键字和它的存储位置之间,通过哈希函数,建立一个确定的对应关系。从而不必在关键字值之间的比较。
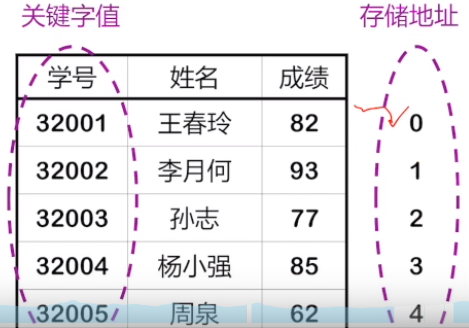
由图可以得出存储地址和关键字值的对应关系是:存储地址 = 关键字值 - 32001,这个就是哈希函数。
但是,并不能保证每次都能构造出理想的哈希函数,因此要构建哈希表。哈希表中的存储地址就是哈希地址。
根据设定的哈希函数和处理冲突的方法,将查找表中各元素存储在一段有限的连续空间中,就得到哈希表
二、构造哈希函数的方法
其实关键是找到哈希地址的各种方法,目的为了使冲突变少.
可以根据关键字的长度、哈希表的大小、计算哈希值的时间、关键字的分布情况、查找记录的频率,去选择哪种不同的哈希函数方法。
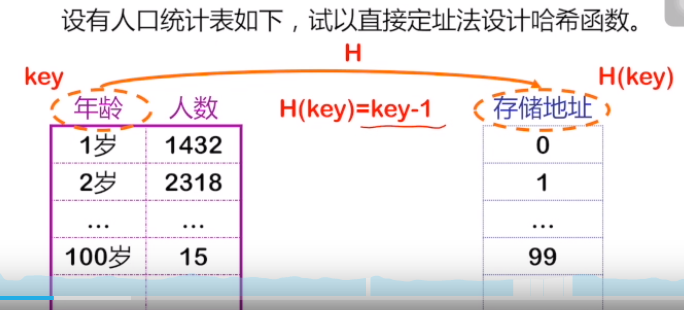
1. 直接定址法
根据关键字和存储地址的关系构建哈希函数
2. 数字分析法
通常用于处理关键字位数比较大的情况(手机号码、身份证号码)。事先知道关键字的分布并且知道关键字的若干位分布比较均匀,就可考虑用这个方法。
例如身份证,截取后面不同的几位存储(例如5位),H(key) = key % 100000
3. 平方取中法
关键字较短,且不知道关键字的分布的情况
对关键字取平方,然后去中间的几位作为哈希地址。
如key = 1234, key^2 = 1522756,则哈希地址可以是227
4. 折叠法
适用于不知道关键字的分布,且关键字位数较多的情况
移位叠加:由地位到高位分割,再加起来求和,舍去进位
例如图书的ISBN 0-442-20586-4 -> 0442205864 -> 04 | 4220 | 5864 -> 5864 + 4220 + 04 = 10088 ->舍去进位1 -> 0088 = 88
简界叠加: 方法同上,只是把分割的部分,从一端到另一端来回折叠相加,224 + 4685 + 4 = 4909 = 909
5. 除留余数法(常用)

对p必须为质数,如果不是质数,则哈希值会落到p倍数的地址上,增加了哈希冲突的可能。
6. 随机数法
取关键字的随机函数作为哈希地址。
H(key) = random(key)
三、处理哈希冲突的方法
哈希冲突是待插入哈希表的元素,按照给定的哈希函数求得的哈希地址已被占用,则按照一定的规则求下一个哈希地址,循环往复,直到找到可用的地址保存该元素
1.线性探测再散列
d = 1,2,3,4,5,6

2. 二次探测再散列
方法同上,只是d = 1^2, -1^2, 2^2, 2^-2 ……k^2,-k^2
二次探测的次数比一次的多,因此较高效

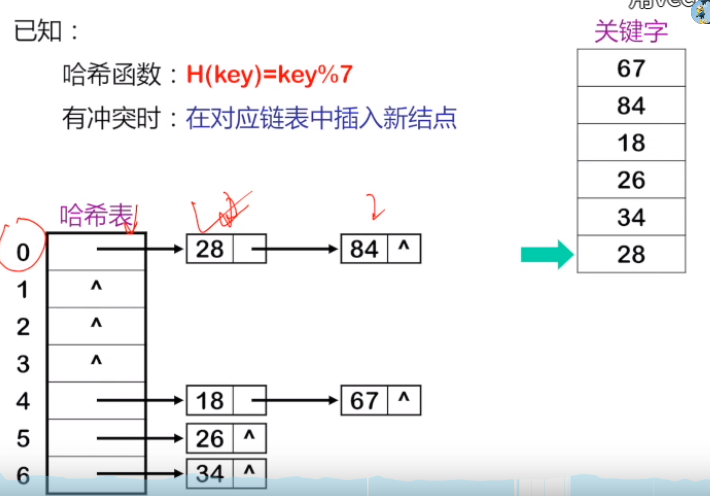
3. 链地址法
按照给定的哈希函数求得哈希地址相同的关键字,存储在同一线性表上,且链表按关键字有序
例如key = (67,84,18,26,34,28)
4. 公共溢出区法
把冲突的关键字放到公共溢出的区域

7,8,9规定为溢出区
四、在哈希表上查找元素
虽然通过哈希表能建立关键字值和存储位置上的映射,但由于冲突的存在,查找时还是需要进行关键字之间的比较,因此要把平均查找长度(ALS) 和 查找不成功时的比较次数作为衡量查找效率的依据。
根据待查关键字元素,按照给定的哈希函数,找出对应的哈希地址。
若该地址上没有元素,则查找失败
若有元素,则进行关键字值之间的比较
- 若相等,则查找成功
- 不相等,则按照处理冲突的方法求下一个可能存储的地址
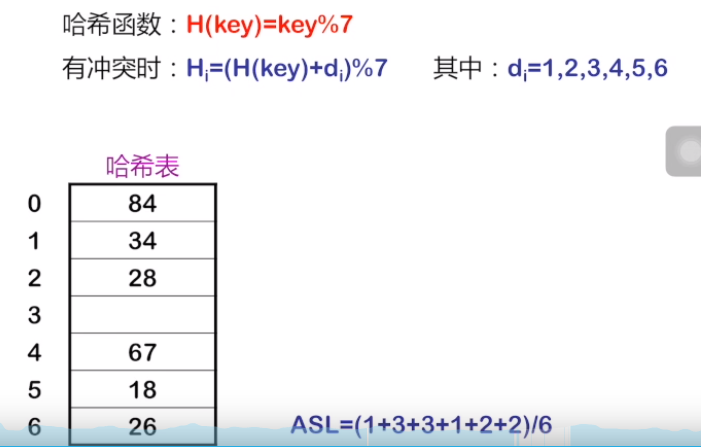
key = 67, 67 % 7 = 4 查找次数1
key = 18 18 % 7 = 4 有冲突 (4+1) % 7 = 5 找到 查找次数为2
哈希通常不会用作数据库索引,因为哈希表不能范围查找和部分索引查找。一旦传入复合索引hash(user_id+name)就不可以了
但是,如果sql语句的查找条件不会变,或者没有范围查找或部分索引查找,可以用hash作为索引的数据结构,并且复杂度是O(1)