一、定义
1 | a := map[string]string{} |
map类型的变量本质上是一个指针,指向hmap结构体
/runtime/map.go
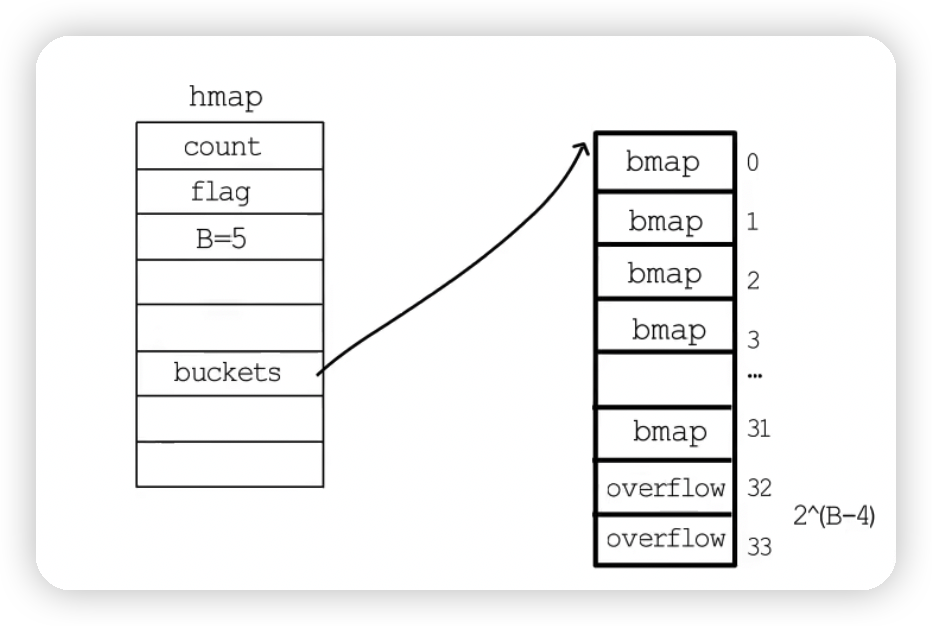
hmap
hmap是哈希表
1 | type hmap struct { |
1 | type mapextra struct { |
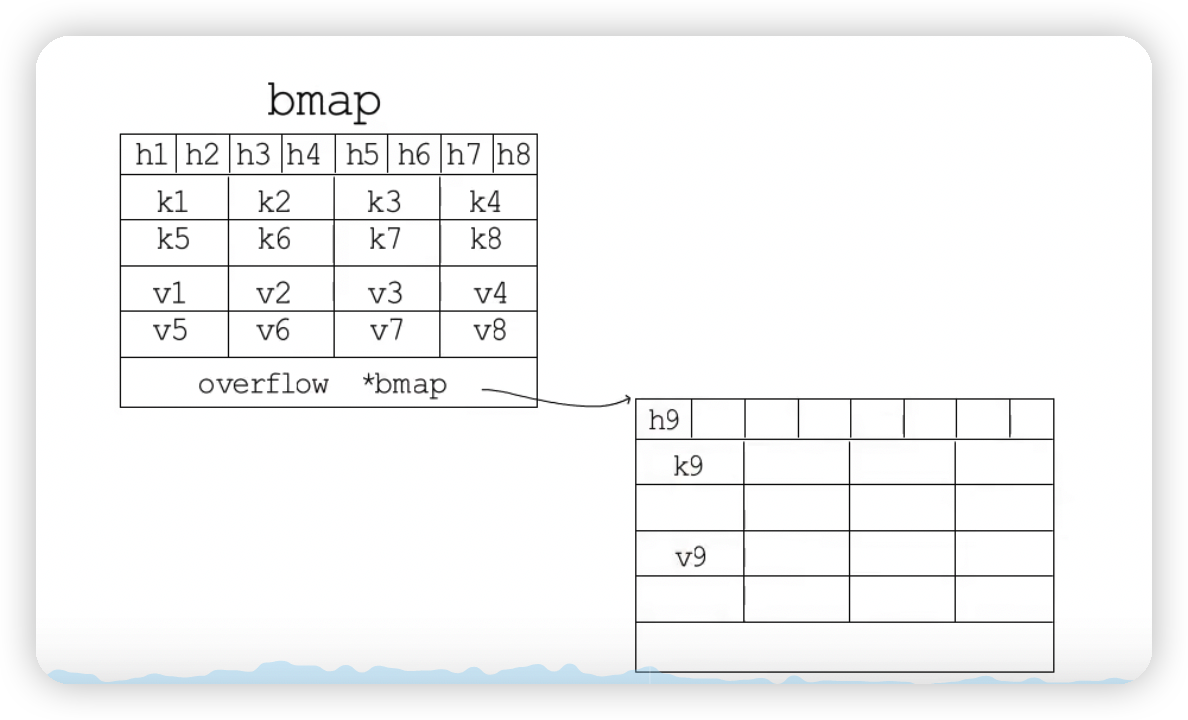
bmap
map使用的桶,即是bmap结构。一个桶可以放8个键值对
1 | bucketCntBits = 3 |
bmap的内存布局:8个key放在一起,8个value放一起。上面是8个tophash,每个tophash都对应哈希值的高8位,目的是为了让内存排列更紧凑。
bmap型指针指向溢出桶,其内存布局和“常规桶”相同,为了减少扩容次数引入的。当一个桶存满了,还有可用的溢出桶时就在桶后面链一个溢出桶。
实际上,哈希表要分配桶的数目B>4,则认为使用溢出桶的概率比较大,会预分配2^(B-4)^个溢出桶备用。
常规桶和溢出桶在内存中是连续的,只是前2^B^个用作常规桶,后面用作溢出桶
1 | // A bucket for a Go map. |
二、Map操作&使用
1、增删
1 | m := make(map[string]int) |
2、并发读写
但是map的使用有一定的限制,如果是在单个协程中读写map,那么不会存在什么问题,如果是多个协程并发访问一个map,有可能会导致程序退出,并打印下面错误信息:

map不支持并发读写,如果有这种场景,需要配合同步机制,如加锁sync.RWMutex,实现对map的并发访问控制 ;或者用sync.map
1 | package main |
3、map中是否存在某个数
1 | if _, ok := mymap[pre]; ok { |
三、Map扩容
对哈希表的扩容是保障读写效率的有效手段
向map插入新key时内存不足,满足以下两个条件则会发生扩容
Load Factor(负载因子) = 6.5 = count (键值对的数目 ) / b(桶的数目 ) loadFactorNum/loadFactorDen , 是判断是否需要扩容的依据
Map的扩容方式
3.1 一次性扩容:
1、分配更多的新桶buckets
2、把旧桶oldBuckets里存储的键值对都迁移到新桶buckets
缺点:
若哈希表里的键值对较多,一次性迁移桶花费的时间长
3.2 渐进式扩容过程
1、一次性分配足够多的新桶buckets,用oldBuckets记录旧桶的位置
2、nevacuate记录下一个要迁移的旧桶编号
3、对哈希表进行读写操作时,若检测到处于扩容阶段,则完成一部分键值对的迁移认为。直到所有的旧桶迁移完成,旧桶不再使用,才算完成一次哈希表的扩容
将键值对迁移的时间分摊到多次哈希表的操作中,可以避免一次性扩容带来的性能瞬时抖动。(redis的rehash)
扩容规则
1、超过负载 (翻倍扩容)
count / 2^b^ > 6.5,则翻倍扩容。扩容后的buckets大小时原来的两倍,并把旧的buckets数据搬到新的buckets
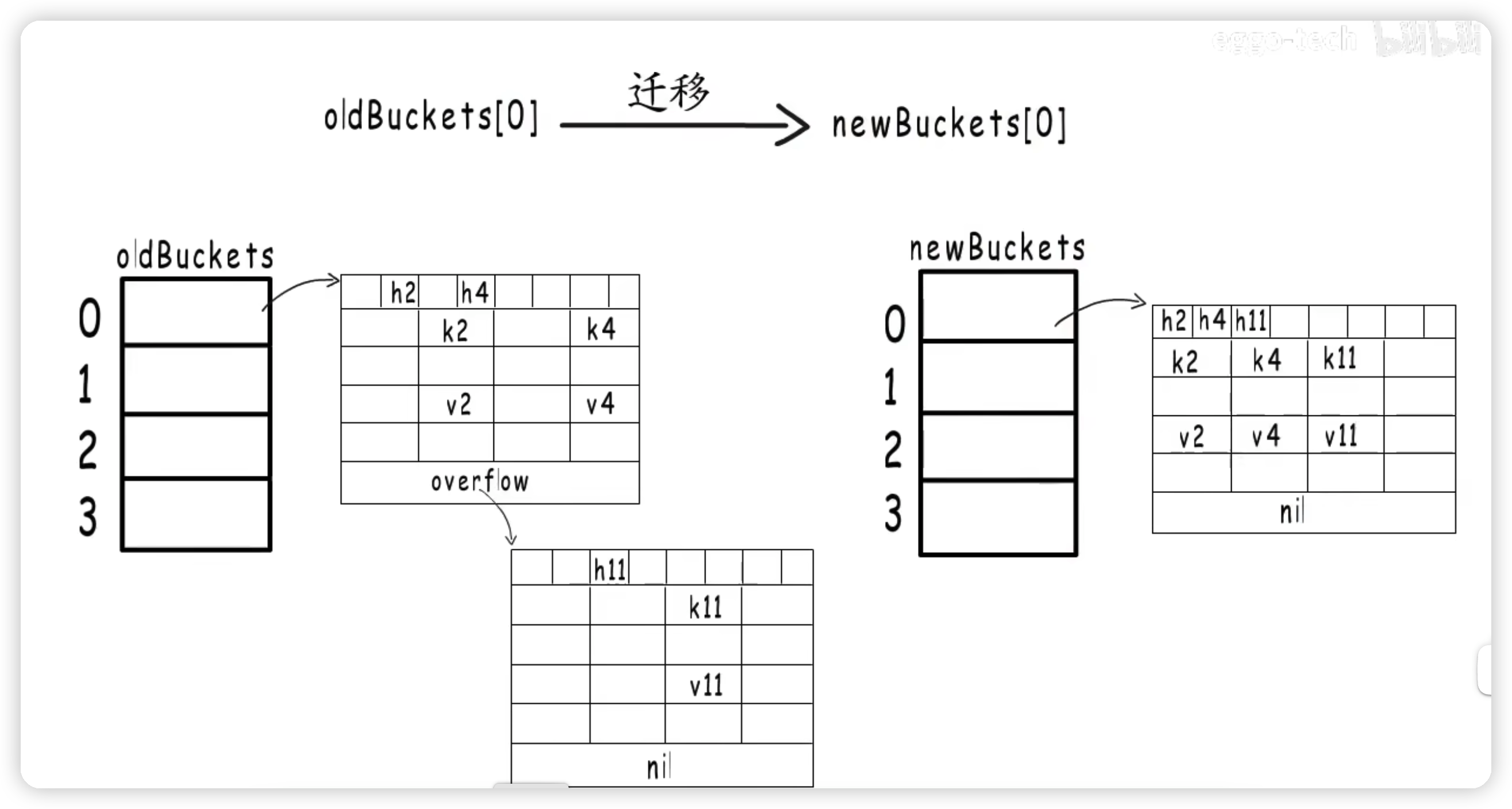
2、溢出桶太多(等量扩容)
等量扩容,就是创建和旧桶数目一样多的新桶,然后把原来的键值对迁移到新桶中。
为什么要这样做呢?等量扩容出现的情况是由于负载因子没有超过上限值,但却使用了很多溢出桶数目。这种情况通常是有很多键值对被删除,如下图编号为0的桶,若此时满足等量扩容的触发条件,编号为0的桶会被迁移到同样编号的新桶,同样数目的键值对迁移到新桶中能够排列得更加紧凑,从而减少溢出桶的使用。
B<=15,noverflow >= 2^B
B>15,noverflow >= 2^15
1 | func tooManyOverflowBuckets(noverflow uint16, B uint8) bool { |
https://go.dev/tour/moretypes/19