前言
在单机开发中,涉及并发同步时,往往使用lock或synchronize的方式实现多线程间代码同步问题。
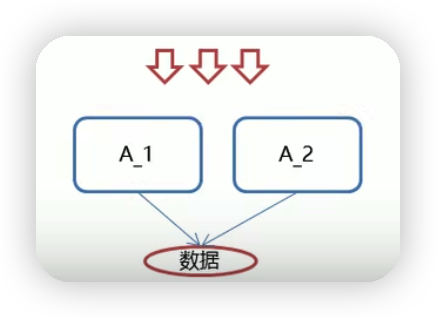
但如果在分布式或者集群环境下就无法通过多线程的锁来解决同步问题,如多个线程同时对服务A_1、A_2进行访问,由于负载均衡权重的原因,两个服务都有可能被访问,即使给服务上锁,也会有两个线程修改同一个数据的风险。
一、分布式锁的介绍
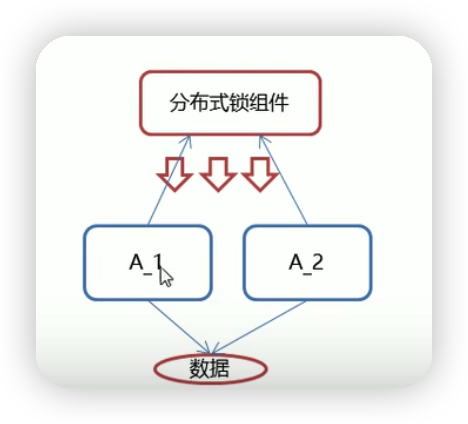
可以引入分布式锁组件,通过分布式组件给集群服务提供唯一的锁。当某个服务需要锁时,向分布式组件申请一个唯一的锁,使用完后释放归还给分布式组件,其它服务才可以申请分布式锁来获取数据。
分布式锁是处理跨机器(JVM)的进程之间的数据同步问题。
二、分布式锁的实现方式
1、缓存(性能高,但不可靠)
用redis做成了集群后,一旦master节点挂了,并且没给其它slave节点同步数据,这个时候可能多个机器都获取到锁
Redis
1
2setnx key value #加锁
del key #释放锁Memcache
2、ZooKeeper实现(性能高,较为可靠)
核心思想:zk客户端想要获取锁,则创建zk节点,使用完锁,则删除该节点。
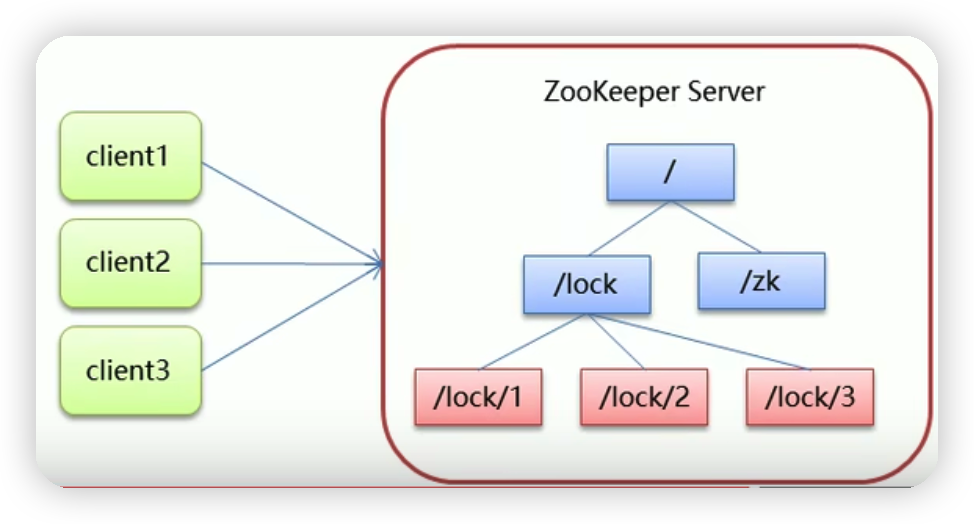
(1)客户端获取在锁时,会在/lock节点下创建临时顺序节点
临时:如果机器在使用过程中宕机了,则会断开客户端和zk的链接,临时节点会在会话结束后删除,因此需要设置临时节点
顺序:需要找最小的节点
(2)然后客户端会获取/lock下面的所有子节点,如果发现自己创建的子节点序号最小,那么被认为获取了锁。锁使用完后则将该节点删除。
(3)若发现自己创建的节点序号并非最小,则说明没有获取到锁,此时客户端需要找到比自己小的一个节点,并同时对其注册监听事件,监听删除事件
(4)若发现比自己小的节点被删除,客户端的Watcher会收到通知,此时再次判断自己创建的节点是不是lock子节点中序号最小。如果是则获取锁,否则重复步骤(2)
3、数据库层面实现(实现方式简单,但性能较低)
- 乐观送
- 悲观锁